31 July 2019

Whenever new technologies emerge, the first priority for a technologist is to understand the implication of adopting it. Serverless architecture is a case in point.
This article has been featured in:
Unfortunately, much of the current literature around serverless architecture focuses solely on its benefits. Many of the articles — and examples used — are driven by cloud providers — so, unsurprisingly talk up the positives. This write-up attempts to give a better understanding of the traits of serverless architecture.
I’ve deliberately chosen the word trait, and not characteristic, because these are the elements of the serverless architecture that you can’t change. Characteristics are malleable, traits are inherent. Traits are also neutral, hence it isn’t positive nor negative. In some cases, the type of trait I’ll describe may have positive connotations, but I’ll be keeping a neutral head on this one so that you understand what you’ll be facing.
Traits are also inherent, hence you’ll have to embrace them, not fight them because such attempts are likely to prove quite costly. Characteristics, on the other hand, need effort spent to mold them, and you can still get them wrong.
I should also point you to this article by Mike Roberts — who also explores the traits of serverless services. Even though we are sharing the same terminology here, it’s useful to note that this article is looking into the traits of your architecture, not the services that you use.
This article doesn’t aim to help you understand all of the topics in-depth but to give you a general overview of what you are in for. These are the traits of serverless architecture defined in this article:
It’s relatively straightforward to start getting your code running in a serverless architecture. You can follow any tutorial to get started and get your code running in a production-grade ecosystem. In many ways, the learning curve for serverless architecture is less daunting than that for typical DevOps skills — many of the elements for DevOps aren’t necessary when you adopt serverless architecture. For instance, you wouldn’t have to pick up server management skills, like configuration management or patching. This is why low barrier-to-entry is one of the traits of serverless architecture.
This means initially, developers have a lower learning curve than many other architectural styles. This doesn’t mean that the learning curve will stay low, and indeed, the overall learning curve gets steeper as developers continue along their journey.
As a result of this architectural trait, I’ve seen many new developers on-boarded to projects very quickly and they’ve been able to contribute effectively towards the project. The ability for devs to get quickly up-to-speed might be one reason that serverless projects have a faster time to market.
As we noted though, things do get more complex. For instance, things like Infrastructure as a code, log management, monitoring, and sometimes networking, are still essential. And you have to understand how you can achieve them in the serverless world. If you’re coming from a different development background, there are a number of serverless architecture traits — which will be covered in this article — that you need to understand.
Despite the initial low barrier to entry, devs shouldn’t assume that they can ignore important architectural principles.
One thing I’ve noticed is the tendency for some developers to think that serverless architecture means they don’t have to think about code design. The justification being that they’re just dealing with functions, so code design is irrelevant. In fact, design principles, like SOLID, are still applicable — you can’t outsource code maintainability to your serverless platform. Even though you can just bundle up and upload your code to the cloud to make it run, I strongly discourage doing this as the Continuous Delivery practices are still relevant in a serverless architecture.
One of the obvious traits of serverless architecture is the idea that you are no longer dealing with servers directly. In this age, where you have a wide variety of host where you can install and run a service — whether it’s physical machines, virtual machines, containers, and so on — it’s useful to have a single word to describe this. To avoid using the already overloaded term serverless, I’m going to use the word host1 here, hence the name of the trait, hostless.
One advantage of being hostless is you’ll have significantly less operational overhead on server maintenance. You won’t need to worry about upgrading your servers, and security patches will automatically be applied for you. Being hostless also means you’ll be monitoring different kind of metrics in your application. This happens because most of the underlying services you use won’t be publishing traditional metrics like CPU, memory, disk size, etc. This means you no longer have to interpret the low-level operational details of your architecture.
But different monitoring metrics mean that you’ll have to relearn how to tune your architecture. AWS DynamoDB exposes read and write capacity for you to monitor and tune, which is a concept that you’ll have to understand — and the learning isn’t transferable to other serverless platforms. Each of the services you use will also have their limitations. AWS Lambda has concurrent executions limit, not the number of CPU cores you have. To make it a little bit quirkier, changing the memory allocation size of your Lambda will change the number of CPU cores you get. If you are sharing one AWS account for your performance testing and production environments, you might bring your production down if the performance test unexpectedly consumes your entire concurrent execution limits. AWS documents the limits for each of these services pretty well, so make sure you check it so that you can make the right architecture decisions.
It’s a common misconception that serverless applications are more secure as security patches are applied to your underlying servers automatically. It’s a dangerous assumption to make.
Traditional security protection wouldn’t be applicable as the serverless architecture has different attack vectors. Your application security practices will still apply, and storing secrets in your code is still a big no-no. AWS has outlined this in its shared responsibility model, where, for example, you still need to secure your data if it contains sensitive information. I highly encourage you to read the OWASP Serverless Top 10 to get more insights on this topic.
While you have significantly less operational overhead, it’s worth noting that in rare cases, you still need to manage the impact of the underlying server change. Your application might be relying on native libraries, and you will need to ensure that they’re still working when the underlying operating system is upgraded. In AWS Lambda, for example, the OS has recently been upgraded to AMI 2018.03.
Functions as a Service, or FaaS, is ephemeral, hence you can’t store anything in memory because the compute containers running your code will automatically be created and destroyed by your platform. Stateless is, therefore, a trait in a serverless architecture.
Being stateless is a good trait to scale applications horizontally. The idea of being stateless is that you are discouraged from storing states in your application. By not storing states in your application, you’ll be able to spin up more instances, without worrying about the application state, to scale horizontally. What I find interesting here is you’re actually forced to be stateless, hence the room for errors is greatly reduced. Yes, there are some caveats: for instance, the compute containers might be re-used and you can store states, but if you take that approach, do proceed with care.
In terms of application development, you won’t be able to utilize technology that requires states, as the burden of state management is forced to the caller. HTTP sessions, for example, can’t be used, as you don’t have the traditional web server with persistent file storage. If you want to use a technology that requires a state like WebSockets, you have to wait until it’s supported by the corresponding Backend as a Service, or apply your own workaround.
As your architecture is hostless, your architecture will have the trait of being elastic as well. Most serverless services that you use are designed to be highly elastic, where you’d be able to scale from zero to the maximum allowed, then back to zero, mostly being managed automatically. Elasticity is a trait of serverless architecture.
The benefit of being elastic is huge for scalability. It means that you won’t have to manage your resources scaling manually. Many challenges of resource allocation disappear. In some cases, being elastic may only mean that you’ll only pay for what you use, hence you’ll lower running costs if you have a low usage pattern.
There are chances that you’ll have to integrate your serverless architecture with legacy systems which don’t support such elasticity. You might break your downstream systems when this occurs, as they might not be able to scale as well as your serverless architecture. If your downstream systems are critical systems, it’s important to think about how you’re going to mitigate this issue — perhaps by limiting your AWS Lambda concurrency or utilizing a queue to talk to your downstream systems.
While ‘denial of service’ is going to be more difficult with such high elasticity, you’ll be vulnerable to ‘denial of wallet’ attacks instead. This is where the attacker s attempts to break application by forcing you to exceed cloud account limits by forcing up your resource allocation. To prevent this attack, you may find it helpful to utilize DDoS protection, such as AWS Shield, in your application. In AWS, it’s also useful to set AWS Budgets, so that you’re notified when your cloud bill is skyrocketing. If high elasticity isn’t something that you’re expecting here, it’s useful again to set a constraint on your application — such as by limiting your AWS Lambda concurrency.
As stateless compute is a trait, all of the persistence requirements you have will be stored in the backend as a service (BaaS), typically a combination of them. Once you embrace FaaS more, you’ll also discover that your deployment units, the functions, are smaller than you may be used to. As a result, serverless architecture is distributed by default — and there are many components that you have to integrate with via the network. Your architecture will also consist of wiring together services, like authentication, database, distributed queue, and so on.
There are many benefits of distributed systems, including elasticity, as we’ve previously discussed. Being distributed also brings a single region, high availability by default to your architecture. In the serverless context, when one availability zone is failing in your cloud vendor’s region, your architecture will be able to utilize other availability zones that are still up — all of which will be opaque from the developers’ perspective.
There is always a trade-off in your choice of architecture. In this trait, you are trading consistency away by being available. Typically in the cloud, each of serverless services has its own consistency model too. In AWS S3, for example, you’ll get read-after-write consistency for PUTS of new objects in your S3 bucket. For object updates, S3 is eventually consistent. It’s quite common for you to have to decide on which BaaS is to be used, so watch out for the behavior of their consistency model.
The other challenge is for you to be familiar with is distributed message delivery methods. You need to be familiar and understand the hard problem of exactly-once delivery, for example, because the common message delivery method for a distributed queue is at-least-once-delivery. An AWS Lambda can be invoked more than once due to this delivery method, therefore you have to make sure that your implementation is idempotent (it’s also important to understand your FaaS retry behavior too, where an AWS Lambda may be executed more than once upon failure). Other challenges that you’ll need to understand include the behavior of distributed transactions. The learning resources in building distributed systems, however, are improving all the time, as the popularity of microservices blooms.
Many of the BaaS provided by your serverless platform will naturally support events. This is a good strategy for third-party services to provide extensibility to their users, as you won’t have any control over the code of their services. As you’ll be utilizing a lot of BaaS in your serverless architecture, your architecture is event-driven by trait.
I also do recognize that you might even though your architecture is event-driven by trait, it doesn’t mean that you need to fully embrace an event-driven architecture. However, I have observed that teams tend to embrace an event-driven architecture when it’s naturally provided to them. This is a similar idea with elasticity as a trait, you can still turn it off.
Being event-driven brings many benefits. You’ll have a low level of coupling between your architecture components. In serverless architecture, it’s easy for you to introduce a new function that listens to a change in a blob store:
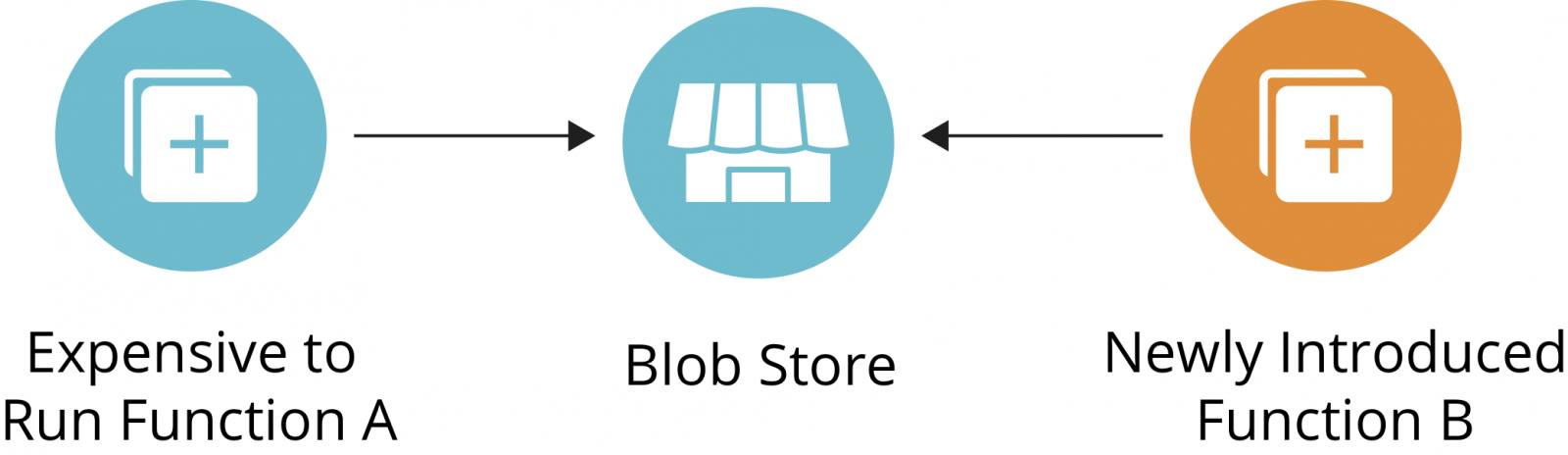 Figure 1: Adding
new serverless functions
Figure 1: Adding
new serverless functions
Notice how function A is not changed when you add function B (See figure 1). This increases the cohesiveness of your functions. There are a lot of benefits of having a highly cohesive function, one of which is that you can easily retry a single operation when it fails. Retrying Function B when it fails means that you wouldn’t need to run the expensive Function A.
Especially in the cloud, the cloud vendors will make sure that it is easy for your FaaS to be integrated with their BaaS. FaaS can be triggered by event notifications by design.
The downside of an event-driven architecture is you may start to lose the holistic view of the system as a whole. This makes it challenging to troubleshoot the system. Distributed tracing is an area that you should look into, even though it’s still a maturing area in serverless architecture. AWS X-Ray is a service that you can use out of the box in AWS. X-Ray does come with its own limitations, and if you’ve outgrown it, you should watch this space as there are third-party offerings that are emerging. This is the reason that the practice of logging Correlation IDs is essential, especially where you’re using multiple BaaS in a transaction. So do make sure that you implement Correlation IDs.
There are six traits of serverless architecture that I have covered in this article: low barrier-to-entry, hostless, stateless, elasticity, distributed, and event-driven. My intention is to go as broad as possible so that you can adopt serverless architecture well. Serverless architecture brought an interesting paradigm shift, which makes a lot of software development aspects better. But it also introduces new challenges that technologists have to get comfortable with. There are also brief recommendations on how you can tackle the challenges each trait would bring, so hopefully, those challenges will not stop you from adopting the serverless architecture.
Thanks to James Andrew Gregory and Troy Towson for a thorough review of this article. Thanks to Gareth Morgan for proofreading and copy-editing this article.
Originally published at www.thoughtworks.com.
The term host is used in the book Building Microservices ↩