21 March 2019

Serverless architecture has fast become a hot topic in tech, thanks partly to its promise of drastically reducing your time-to-market. Nonetheless, many IT leaders remain cautious about serverless because of their fears over vendor lock-in. In this article, I’ll explore the realities of what lock-in means in the context of serverless — and propose strategies to minimize your risks.
There are already a number of views on what constitutes serverless. For the purposes of this piece, I’m using it as described here: application designs that incorporate third-party “Backend as a Service” (BaaS) services, and/or that include custom code run in managed, ephemeral containers on a “Functions as a Service” (FaaS) platform. When thought of in these terms, you can see why lock-in can be a major concern. While serverless architectures might reduce your operational cost, complexity, and engineering lead time, it makes you more reliant on your BaaS provider.
The main reason IT folk fear lock-in is cost, and naturally, we all like to avoid additional costs. When it comes to serverless, it’s not the case that to switch service provider is impossible; it’s just costly. We can think of this as a lock-in cost. Let’s break down what a lock-in cost is:
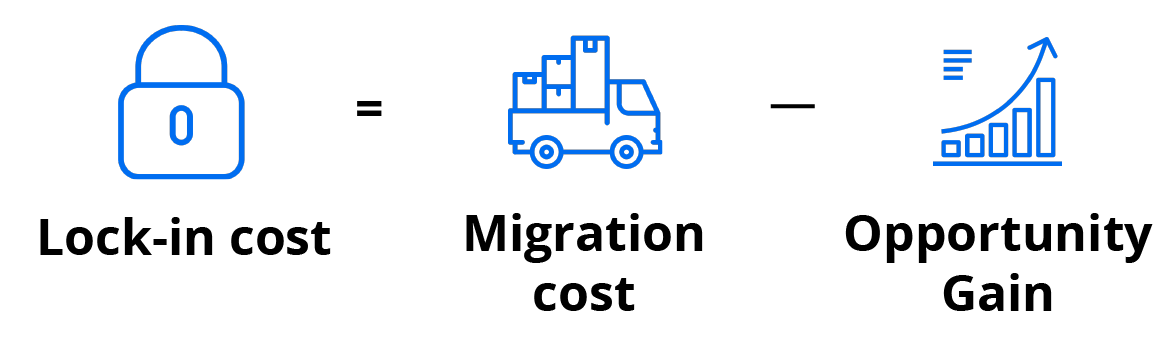 Figure 1: The true lock-in costs aren’t always what you expect
Figure 1: The true lock-in costs aren’t always what you expect
As you can see, for companies considering serverless, lock-in cost isn’t simply the cost of some future migration: we need to account for the benefits that transitioning to serverless will provide today. As I’ve already mentioned, faster time to market is a big selling point for serverless architecture, which is translated to opportunity gain for the business. Notice also that the operator in that formula is a minus sign; hence the ‘cost’ could be zero or even a profit.
With the equation in mind, these are the ways you can reduce a lock-in cost:
There are two ways you can maximise your opportunity gain:
To be as cloud-native as possible, you might want to utilize the BaaS that your cloud vendor has provided, and avoid the trap of the cloud lowest common denominator. Let’s take a practical example of how this works. Say we’ve adopted serverless architecture in AWS; when we’d like to fire an event, we’d normally be faced with two options: Kinesis (AWS only) or Kafka (self-installed, assuming that you don’t have one in your platform yet). By using Kinesis, you’re maximising your opportunity gain: you’ll be utilizing the platform as much as possible and increase your chances of getting a faster time to market. But if the fear of vendor lock-in means you choose Kafka, you’ll find yourself investing time setting up a server, installing the software, adopting all of the best practices, and making sure that your Kafka cluster can scale.
With the cloud platforms that are fast moving at the moment, it is also very quick for your current evaluation to be invalid. Even if maybe GCP is not having an equivalent of Kinesis at the moment, the platform might have already evolved in the point of your migration, and you can migrate to a similar service.
Just like any other kind of architecture, following common industry practices can help minimize migration cost — so it’s important to think these through when considering the potential cost of lock-in.
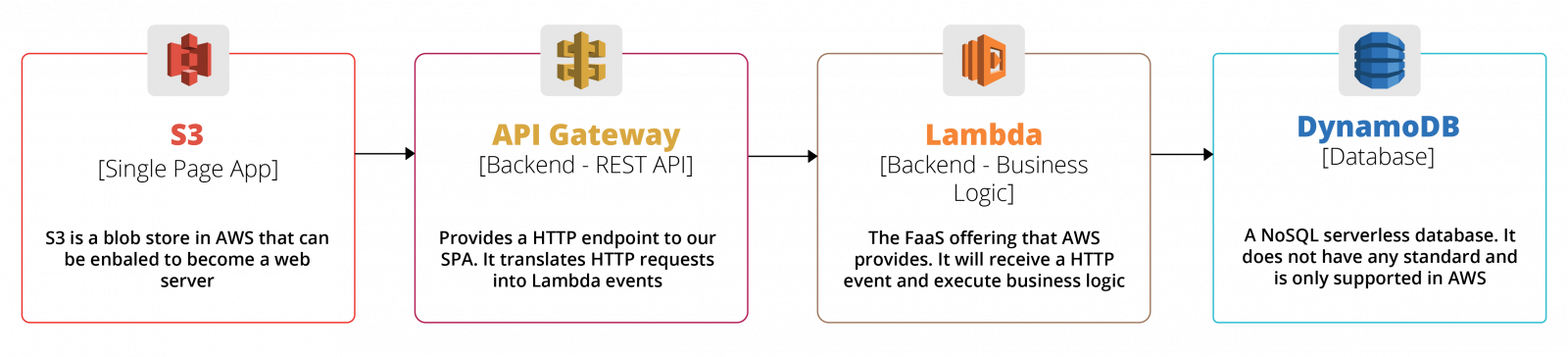 Figure 2: An example of a serverless application
Figure 2: An example of a serverless application
Before doing anything else, it’s important to check which programming languages are supported by the vendors you’re considering. For example, at the time of writing, NodeJS, Python, and Go are the only supported languages in Google Cloud Function. Migrating to a competing vendor that is supporting the same programming language would definitely reduce your Lambda migration cost.
Once you’re confident that your new vendors support your chosen language, it’s time for the next challenge. You’ll discover that one of the biggest migration problems in the serverless world is not the Lambdas you’ve written but their ecosystem — the various fully managed services that your existing cloud partner provides.
Typically, when we’re looking to make migrations easier, we look to abstraction. For instance, operating systems abstract you away from hardware; virtualizations abstract you away from operating systems. The abstraction that we need in serverless is a good architecture pattern.
I might not be able to emphasize this enough, but the initial learning curve of FaaS is quite low — that might mean you’re tempted to pay less heed to your architecture pattern. I’d caution against that: a good architecture pattern will make any future migrations of Lambdas much easier. One a good architecture pattern that you can adopt is the Hexagonal architecture, where your application is isolated from external concerns. Here’s an example of how you can apply the Hexagonal architecture to your Lambda:
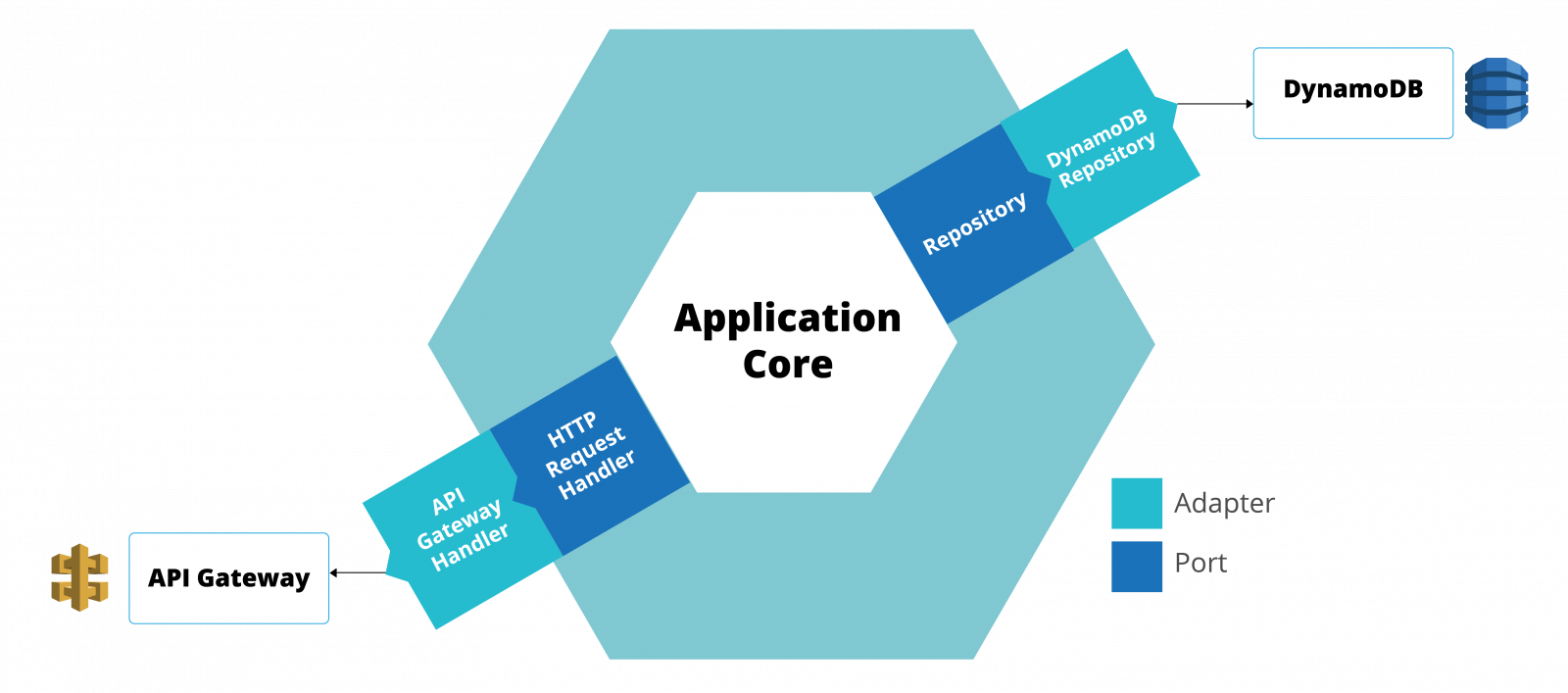 Figure
3: Applying Hexagonal architecture to your Lambda
Figure
3: Applying Hexagonal architecture to your Lambda
Notice how the core of your application is not dependant on the AWS ecosystem. Your migration cost will be reduced as your application core code won’t change during migration, and you’d only need to write and plug new adapters to it.
Unit tests which are coupled to one vendor will be costly to migrate. This shouldn’t be a problem if you’ve adopted a good architecture pattern (see the previous section). In AWS Node.js for example, if you find that you need aws-sdk-mock, make sure that the subject under test is purely designed to talk to AWS services — and not your business logic.
As more and more components in your architecture are managed by your cloud vendor, integration tests are becoming ever more important. Your integration tests will need to talk to your cloud vendor’s services in the integration tests. Tests that are heavily dependant on cloud vendor are costly to migrate. If you’ve adopted a good architecture pattern, you should be able to reuse the abstraction that you’ve written for your application. The following example shows how a DynamoDB Repository class can be reused by the backend, integration test and acceptance test:
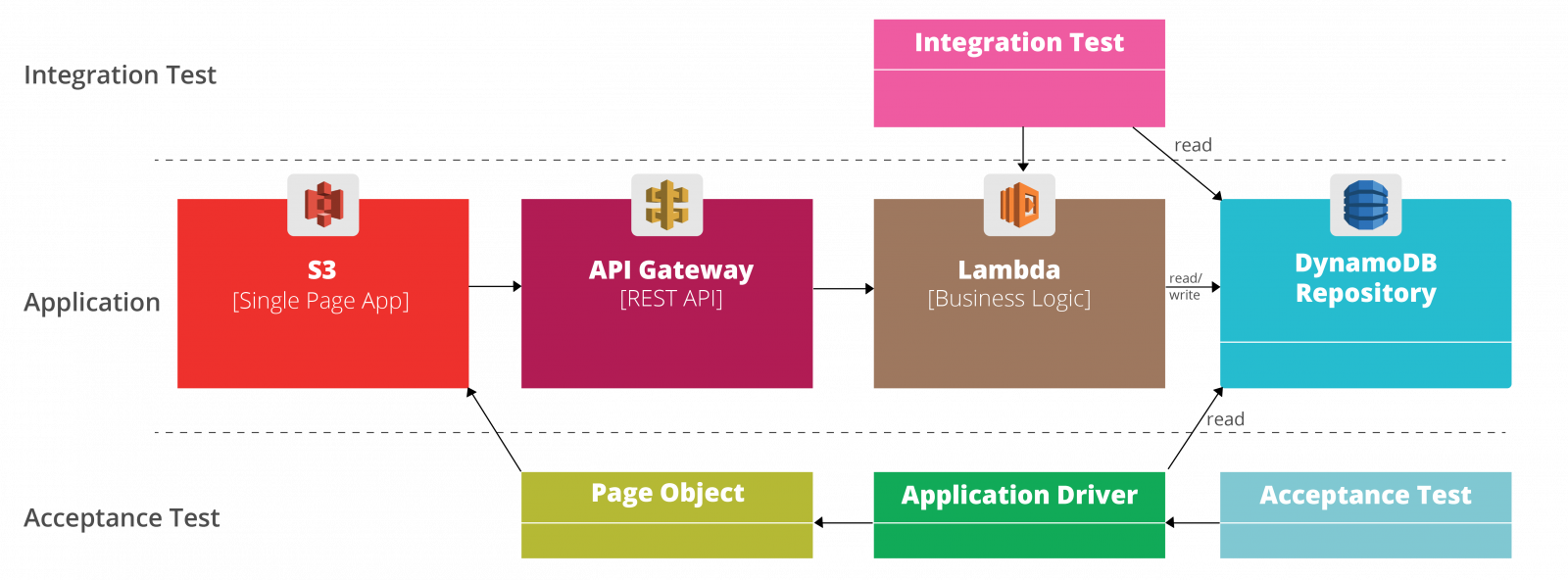 Figure 4: A DynamoDB
Repository class can be reused by the backend, integration test and acceptance
test
Figure 4: A DynamoDB
Repository class can be reused by the backend, integration test and acceptance
test
HTTP is your friend here. HTTP web server today is a commodity and should be
supported by every vendor. If that wasn’t the case, it could be implemented by
installing your own web server. Therefore, the migration cost of your frontend
code to other vendors should be close to zero, as your SPA shouldn’t change at
all.
The cost of migrating away from API Gateway should be low too, both in the
frontend and backend. Your frontend code is abstracted away by HTTP when it is
talking to the backend. The use of AWS API Gateway to translate HTTP events to
Lambdas is also a common use case that should already be supported by most
vendors.
If RDBMS fits your use case, SQL is another kind of standard that you can use. AWS, for example, has Serverless Aurora, which is a MySQL-compatible database that will naturally ease the migration path to your new vendor’s MySQL-compatible database.
Apart from the above, there is an active work of standardization called CloudEvents, which is the work of CNCF Serverless Working Group Watch.
If you’re looking to adopt serverless architecture and worried about lock-ins, hopefully, this article has put you at ease. When you’re worried about vendor lock-in, break down the high lock-in cost that worries you instead. Adopting serverless in full will give you a faster time to market, so think about the cost of opportunity as well in today’s highly competitive market. It’s possible to adopt serverless with low migration cost, and most of the practices that have been outlined here are not new. In fact, these I could argue that these practices should be applied regardless of whether you are adopting serverless or not.
Originally published at www.thoughtworks.com.